Способ распознавания рукопечатного символа из текстового источника
Номер патента: 16050
Опубликовано: 30.06.2012





Текст
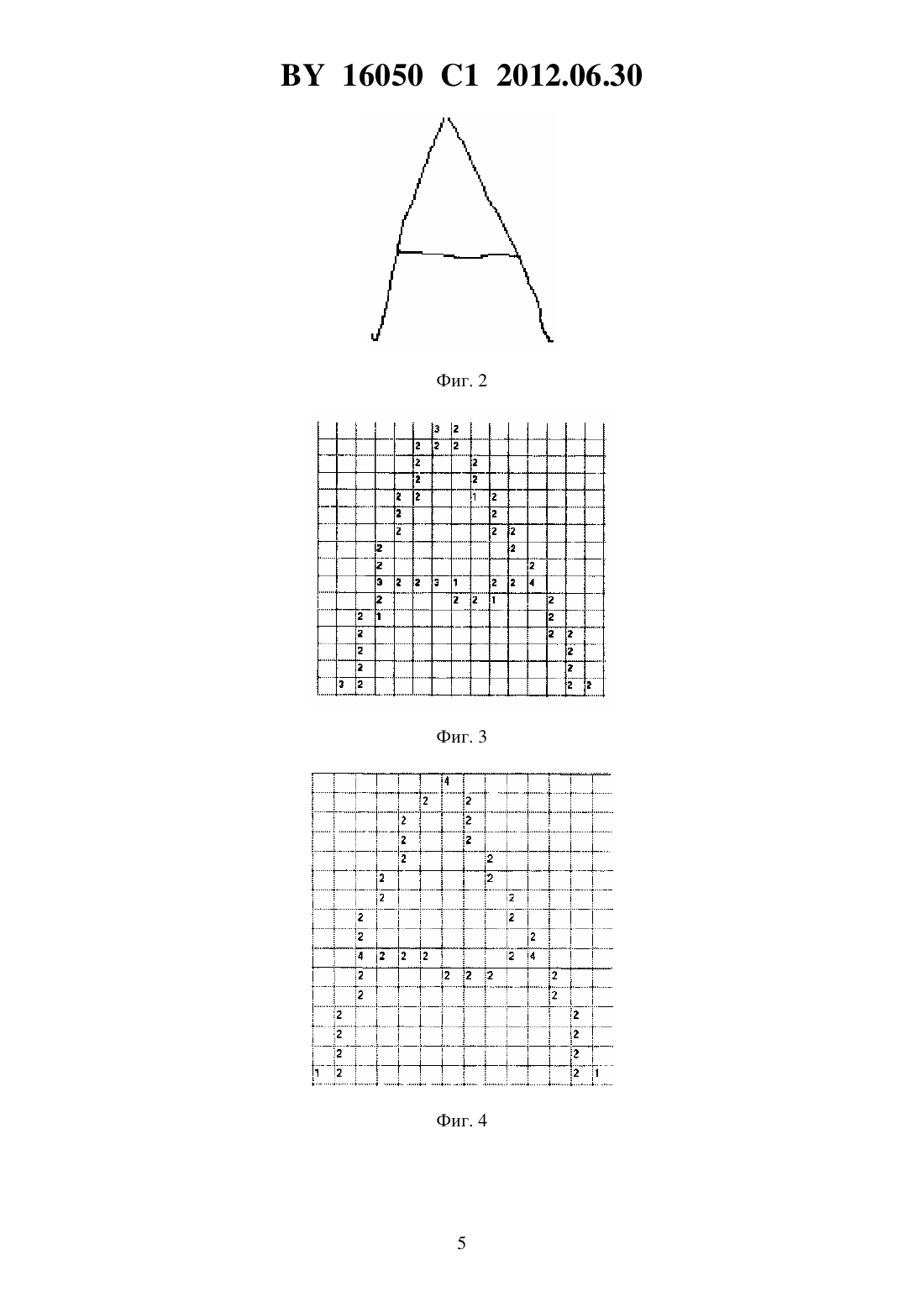
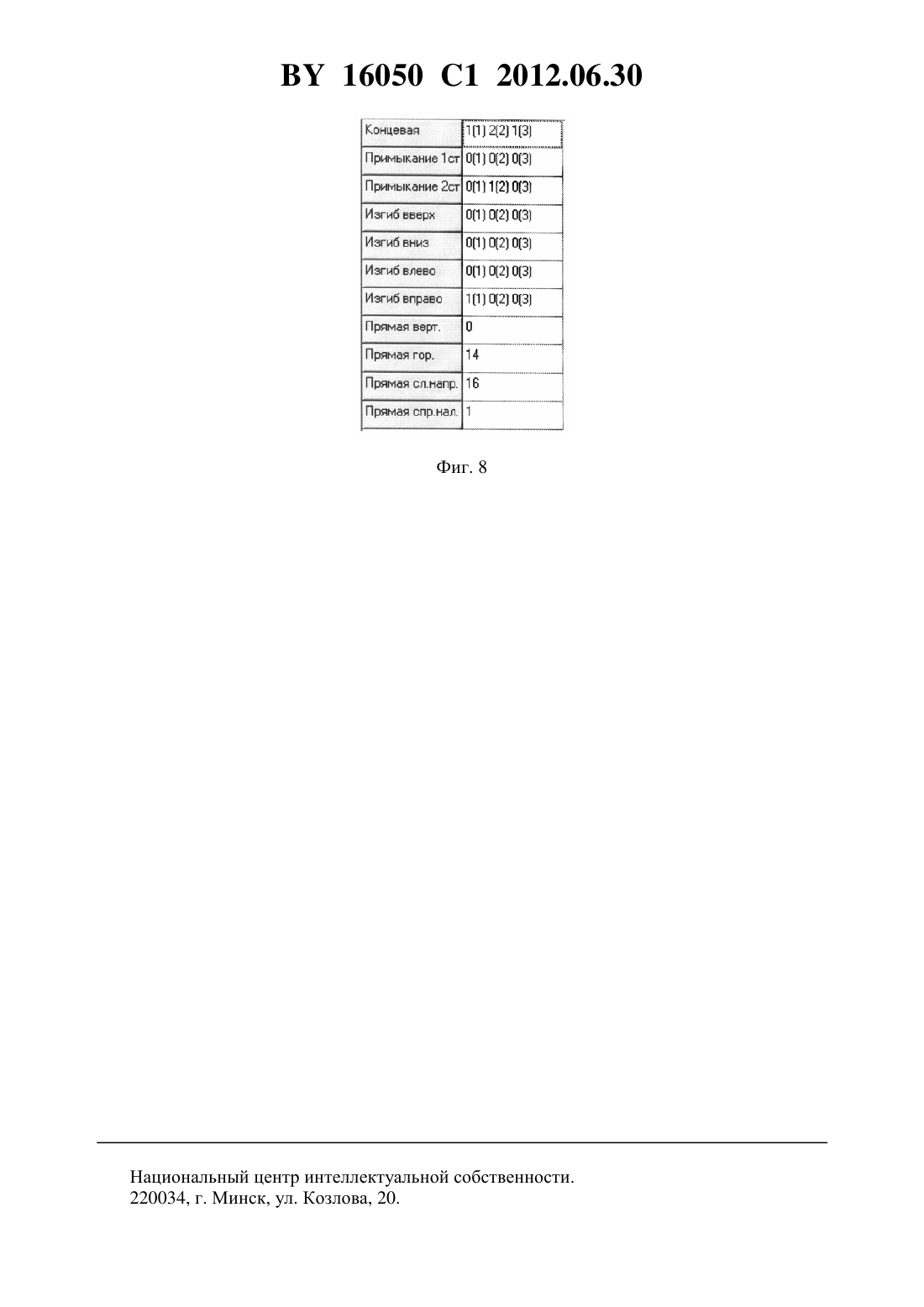
(51) МПК НАЦИОНАЛЬНЫЙ ЦЕНТР ИНТЕЛЛЕКТУАЛЬНОЙ СОБСТВЕННОСТИ СПОСОБ РАСПОЗНАВАНИЯ РУКОПЕЧАТНОГО СИМВОЛА ИЗ ТЕКСТОВОГО ИСТОЧНИКА(71) Заявитель Учреждение образования Полоцкий государственный университет(72) Авторы Вихров Александр Геннадьевич Богуш Рихард Петрович(73) Патентообладатель Учреждение образования Полоцкий государственный университет(57) Способ распознавания рукопечатного символа из текстового источника, в котором выполняют логическую фильтрацию и скелетизацию изображения распознаваемого символа из текстового файла, разбивают полученное изображение на блоки и выделяют в каждом блоке соответствующий ему дескриптор формы, выбранный из следующей группы а) концевой б) примыкание первой степени в) примыкание второй степени г) изгиб вверх д) изгиб вниз е) изгиб влево ж) изгиб вправо з) вертикальная прямая и) горизонтальная прямая к) наклон слева направо л) наклон справа налево, Фиг. 1 16050 1 2012.06.30 каждый компонент которой имеет вид, показанный на фигуре 1, затем строят из выделенных по всем блокам дескрипторов двумерную матрицу распознаваемого символа, уточняют виды, положение и результирующее количество дескрипторов в матрице с помощью масок, объединяют уточненные дескрипторы в следующие семейства К - семейство концевых ППС - семейство примыкания первой степени ПВС - семейство примыкания второй степени СПИ - семейство прямых и изгибов,после чего строят из дескрипторов, принадлежащих указанным семействам, уточненную двумерную матрицу символа, которую разбивают на одинаковые верхнюю, центральную и нижнюю области, далее производят фильтрацию дескрипторов из семейств К, ППС и ПВС для уточнения их положения в матрице и определяют вектор уточненных дескрипторов, и затем сравнивают полученный вектор по семействам К, ППС и ПВС поочередно в каждой из указанных областей с эталонными векторами с распознаванием символа в случае получения однозначного результата сравнения, а в случае получения нескольких равнозначных результатов сравнения дополнительно сравнивают вектор дескрипторов с эталонными векторами по семейству СПИ до получения однозначного результата сравнения. Заявляемое изобретение относится к области информатики и может быть использовано для распознавания текстовой информации в различных системах, включая системы распознавания рукопечатных символов в реальном режиме времени. Известен способ распознавания рукопечатных символов текстовой информации из векторно-растрового изображения 1, включающий последовательность следующих действий выполняют последовательное разбиение изображения до получения областей, содержащих неразрывный логически связанный текст наибольшего размера обрабатывают текстовые объекты проводят анализ и составление групп символов строки после сборки строк делят строку на слова, по пробелам там, где они есть, и анализируя интервалы между символами там, где пробелов нет обрабатывают векторные объекты обрабатывают растровые объекты удаляют избыточную и излишнюю информацию после разбиения на строки и слова проводят анализ корректности кодировки символов, при необходимости исправляют если не удается получить текст другими известными способами, текстовый блок направляют на распознавание. Недостатками известного способа являются необходимость в значительных вычислительных ресурсах, низкая вероятность правильного определения объекта и выявления необходимой текстовой области. Способ предполагает наличие фильтрации для удаления избыточной и излишней информации, однако при этом уменьшается точность и скорость распознавания символов. В качестве прототипа выбран способ распознавания рукопечатных символов текстовой информации из графического файла с использованием словарей и дополнительных данных 2, предполагающий выполнение следующих действий предварительно задают порядок обращения к дополнительной информации назначают оценку качества для каждого вида дополнительной информации строят различные варианты разбиения изображения выделенных строк на фрагменты 2 16050 1 2012.06.30 для каждого фрагмента строки строят граф линейного деления распознают изображения графических элементов, используя классификатор, и каждому варианту распознавания присваивают оценку выполняют переход от вариантов распознавания графем к вариантам символов алфавита для каждой цепочки, соединяющей начальную и конечную вершины, строят цепочки,соответствующие всем вариантам распознавания графем и вариантам переходов от распознанных графем к символам алфавита ранжируют полученные варианты в порядке уменьшения оценки качества распознавания обрабатывают полученные варианты с привлечением информации о расположении заглавных и строчных букв и каждому полученному варианту назначают оценку качества варианты символов, имеющие оценку ниже предварительно заданной, отбрасывают,полученные варианты сортируют, используя попарное сравнение используя попарное сравнение, производят дополнительную коррекцию распознавания пробелов, ошибочно распознанных на предыдущих этапах. Недостатком прототипа являются значительные вычислительные затраты при ранжировании графем и сортировке попарных символов, имеющие оценку ниже предварительно заданной. Задачей изобретения является сокращение вычислительных затрат на обработку символа, повышение точности его распознавания и, за счет этого, повышение эффективности функционирования систем распознавания рукопечатных символов в целом. Поставленная задача решается тем, что в способе распознавания рукопечатного символа из текстового источника, в котором выполняют логическую фильтрацию и скелетизацию изображения распознаваемого символа из текстового файла, разбивают полученное изображение на блоки и выделяют в каждом блоке соответствующий ему дескриптор формы, выбранный из следующей группы а. концевой б. примыкание первой степени в. примыкание второй степени г. изгиб вверх д. изгиб вниз е. изгиб влево ж. изгиб вправо з. вертикальная прямая и. горизонтальная прямая к. наклон слева направо л. наклон справа налево,каждый компонент которой имеет вид, показанный на фиг. 1, затем строят из выделенных по всем блокам дескрипторов двумерную матрицу распознаваемого символа, уточняют виды, положение и результирующее количество в матрице с помощью масок, объединяют уточненные дескрипторы в следующие семейства К - семейство концевых ППС - семейство примыкания первой степени ПВС - семейство примыкания второй степени СПИ - семейство прямых и изгибов,после чего строят из дескрипторов, принадлежащих указанным семействам, уточненную двумерную матрицу символа, которую разбивают на одинаковые верхнюю, центральную и нижнюю области, далее производят фильтрацию дескрипторов из семейств К, ППС и ПВС для уточнения их положения в матрице и определяют вектор уточненных дескрипторов, и затем сравнивают полученный вектор по семействам К, ППС и ПВС поочередно в 3 16050 1 2012.06.30 каждой из указанных областей с эталонными векторами с распознаванием символа в случае получения однозначного результата сравнения, а в случае получения нескольких равнозначных результатов сравнения дополнительно сравнивают вектор дескрипторов с эталонными векторами по семейству СПИ до получения однозначного результата сравнения. Сущность заявляемого способа поясняется изображениями, представленными на фиг. 1-8. На фиг. 1 представлены дескрипторы формы а) концевой, б) примыкание первой степени, в) примыкание второй степени, г) изгиб вверх, д) изгиб вниз, е) изгиб влево, ж) изгиб вправо, з) вертикальная прямая, и) горизонтальная прямая, к) наклон слева направо,л) наклон справа налево на фиг. 2 - пример рукопечатного символа, полученного из файла на фиг. 3 - результат выполнения предобработки символа с фиг. 2 и выделения дескрипторов формы на фиг. 4 - результат выполнения этапа фильтрации семейства дескрипторов на фиг. 5 - таблица дескрипторов буквына фиг. 6 - второй пример рукопечатного символа, полученный из файла на фиг. 7 - результат выполнения логической фильтрации и скелетизации символа на фиг. 8 представлена таблица дескрипторов цифры 7. Примеры осуществления заявляемого способа. Пример 1 Выделяют рукопечатный символ из текстового файла и выполняют логическую фильтрацию и скелетизацию этого символа (фиг. 2). Такой подход характерен для офлайнсистем распознавания рукопечатных символов. Затем разбивают символ на блоки и по каждому блоку выделяют дескриптор. Полученные дескрипторы объединяют в семейства и строят двумерную матрицу семейства дескрипторов (фиг. 3). Далее проводят фильтрацию семейства К, ППС и ПВС. Фиг. 4 отображает результат выполнения этапа фильтрации семейства дескрипторов. Следующим шагом определяют вектор окончательно обработанных дескрипторов (фиг. 5). По этапу сравнения полученного вектора дескрипторов с эталонными векторами дескрипторов определяют степень схожести. Символиз базы эталонов имеет наибольшую степень схожести и поэтому он выдается в качестве искомого. Пример 2 Получают символ, считанный с сенсорного устройства (фиг. 6). Данная методология распознавания рукопечатных символов характерна для онлайн-систем. Результат выполнения логической фильтрации и скелетизации символа с результатом фильтрации семейств дескрипторов изображены на фиг. 7. Формируют окончательный вектор дескрипторов (фиг. 8). Сравнивают полученный вектор дескрипторов с эталонными векторами дескрипторов. Определяют степень схожести. Символ 7 из базы эталонов имеет наибольшую степень схожести и поэтому он выдается в качестве искомого. Сокращение вычислительных затрат достигается за счет использования минимального набора эталонных символов, которые формируются в зависимости от сложности задачи распознавания. Повышение точности распознавания символов обеспечивается за счет эффективного набора дескрипторов при структурном анализе рукопечатного текстового символа, а также за счет того, что дескрипторы концевая, примыкания и изгибы определяются в отдельных областях - в верхней, центральной и нижней, а остальные определены по всей области расположения символа. Источники информации 1. Патент Российской Федерации 2309456, МПК 06 9/36, опубл. 27.10.2007. 2. Патент Российской Федерации 2295154, МПК 06 9/68, опубл. 10.03.2007 (прототип). 4 Национальный центр интеллектуальной собственности. 220034, г. Минск, ул. Козлова, 20. 7
МПК / Метки
МПК: G06K 9/68, G06F 17/21
Метки: способ, источника, текстового, символа, распознавания, рукопечатного
Код ссылки
<a href="https://by.patents.su/7-16050-sposob-raspoznavaniya-rukopechatnogo-simvola-iz-tekstovogo-istochnika.html" rel="bookmark" title="База патентов Беларуси">Способ распознавания рукопечатного символа из текстового источника</a>
Способ распознавания речевых образов преимущественно для текстозависимой верификации диктора по речевому сигналу и устройство для его осуществления

Номер патента: 9430
Опубликовано: 30.06.2007
Авторы: Рылов Александр Сергеевич, Чижденко Виктор Анатольевич
МПК: G10L 17/00, G10L 15/00
Метки: преимущественно, текстозависимой, верификации, речевому, осуществления, устройство, диктора, речевых, сигналу, распознавания, образов, способ
Текст:
...речевых образов, включающий создание множества эталонных моделей для каждого класса образов, сравнение эталонных моделей с тестовой реализацией и принятие решения о распознавании (патент 70 Не 9919865, МПК 6 1 ОЬ 5/06, опубл. 22. 04. 99). Причем для повышения помехоустойчивости способа распознавания при возникновении каких-либо условий несопоставимости режимов обучения и распознавания (акустические условия, эмоциональные состояния дикторов...
Устройство корреляционного распознавания бинарных образов

Номер патента: U 1748
Опубликовано: 30.03.2005
Авторы: Татур Михаил Михайлович, Жолтиков Руслан Романович
МПК: G06K 9/00
Метки: корреляционного, распознавания, бинарных, образов, устройство
Текст:
...ошибки для символов К, И, Н и т.д.Полезная модель направлена на повышение вероятности распознавания или, что то же самое, на снижение вероятности ошибки при распознавании бинарных изображений, нечетко совпадающих с эталоном.При неполном совпадении распознаваемого изображения с эталоном часть пикселей эталона, расположенных на границе объекта и фона, являются менее информативными,чем остальные пиксели изображения. Исключение этих пикселей из...
Способ обнаружения и распознавания радиолокационных объектов

Номер патента: 1742
Опубликовано: 30.09.1997
Авторы: Дещенко Геннадий Николаевич, Михнев Валерий Александрович, Максимович Елена Степановна, Любецкий Николай Васильевич
МПК: G01S 13/00
Метки: объектов, радиолокационных, обнаружения, способ, распознавания
Текст:
...которой кодируют по закону псевдослучайной последовательности направление вращения отраженной кругополяризованной волны путем изменения на 180 разности фаз между ее ортогонально поляризованными составляющими, непрерывно определяют поляризацию отраженной волны и находят значение взаимнокорреляционной функции по известной кодированной зависимости. Сущность предложенного способа основывается на следующих положениях. Для повышения дальности и...
Устройство распознавания диктора

Номер патента: U 4214
Опубликовано: 28.02.2008
Авторы: Лыньков Леонид Михайлович, Давыдов Геннадий Владимирович, Шамгин Юрий Васильевич, Давыдов Андрей Геннадьевич, Воробьев Василий Иванович
МПК: G10L 15/00
Метки: диктора, распознавания, устройство
Текст:
...последовательно, коммутатор, блок сравнения параметрических описаний эталона и входного речевого сигнала, блок принятия решения о распознаваемом дикторе и запоминающее устройство, при этом источник речевого сигнала подключен к блоку определения параметрического описания речевого сигнала, выход которого соединен с входом коммутатора, первый выход которого подключен к первому входу блока сравнения параметрических описаний эталона и...
Устройство автоматического распознавания диктора по речи

Номер патента: U 6754
Опубликовано: 30.10.2010
Авторы: Аль-Хатми Мохаммед Омар, Зельманский Олег Борисович
МПК: G10L 15/00
Метки: речи, автоматического, диктора, распознавания, устройство
Текст:
...Фурье, вычислителя спектра мощности сигнала в сегменте, блока определения формантного вектора текущего сегмента и формирователя параметрических описаний входного речевого сигнала, соединенных последовательно, коммутатор, блок сравнения параметрических описаний эталона и входного речевого сигнала, блок принятия решения о распознаваемом дикторе и запоминающее устройство. Недостатком такого устройства является то, что оно все еще не обеспечивает...
Предыдущий патент: Устройство для вычисления полиномиальных симметрических булевых функций n переменных
Следующий патент: Способ изготовления детали узла трения скольжения
Случайный патент: Модуль массообменный гемосорбционный